担当工程
| PM |
基本設計 |
詳細設計 |
構築 |
導入 |
保守 |
| ○ |
○ |
○ |
○ |
○ |
○ |
※横にスクロールします
事例概要
事例説明
パブリッククラウドサービスでは信頼性が高いインフラ設計はされておりますが、
それでも障害によるサービス停止を免れることはできません。
この事例では独自に設計・実装した障害検知・切替の仕組みにより複数のクラウドサービスを用いた、
非常に可用性が高いサービス提供環境を実現しました。
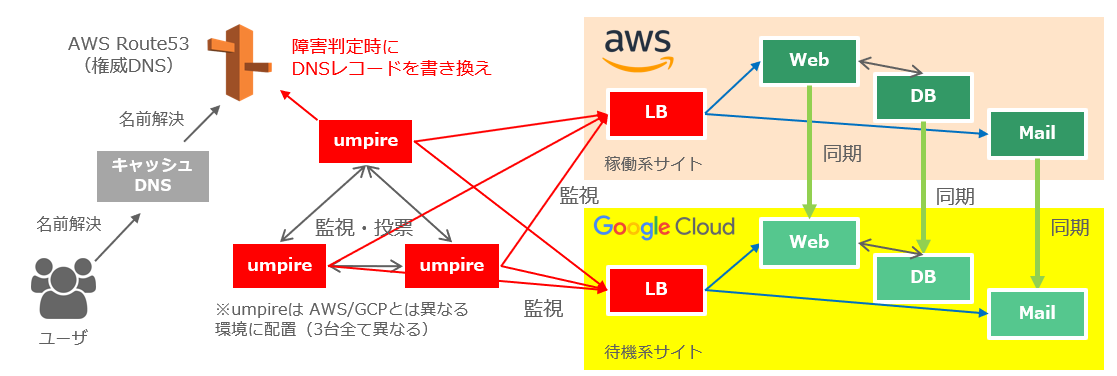
サービス監視には独自に設計した「umpire」というサーバを用います。
umpireは Web/DB/Mail の各サービスを監視し、
監視ステータスの多数決により障害と判定された場合には権威DNS (Route53) のDNSレコードを書き換えます。
この事例ではDNSレコードを適切に調整することで、
レコード書き換えからクライアントPCのDNSキャッシュを更新するまでの時間は30秒程度となっています。
この仕組みにより、クラウド側で障害が発生した場合でも非常に短時間で待機系のサイトに切り替えることができます。
この事例でのサービスはWebサーバ、バックエンドのDBサーバ、メールサーバ (MTA、MRA) で提供されています。
各サーバの同期の実装方式は異なりますが、ほぼリアルタイムに近い同期を実現しています。
障害と判定された場合には umpireはこちらも独自設計・実装のロードバランサ (LB) と連携して
障害判定されたサーバへの通信を停止します。
これにより障害発生直後の稼働系サイトでのトランザクションを極力減らし、データの整合性を確保します。
この構成でCDNを用いることなく、低予算でアクティブ/スタンバイ構成のマルチクラウドが実現できました。